
Configuring Iterations for Teams in Azure DevOps
2021-07-11 14:59
I don't know how much guidance Microsoft gives on creating Iterations. This is my approach.
The Basics
Here's the Azure DevOps structure, regardless of usage:
|_Process [Work items defined]
|_Project(s) [Iterations defined]
|_Team(s) [Board defined, Iterations selected]
|_Area(s)
|_Work Item(s) [assigned to Area and Iteration]
There's always a top-level "iteration" with the name of the project, which can't be changed. This is confusing because everything in the iteration tree is called an iteration, but in fact you should think of the tree as folders of iterations.
You configure iterations at the project level (Project Settings > Boards > Project configuration). However, a Team chooses which iterations it uses. In other words, adding iterations to the project does not add them to all teams.
While initially confusing, this gives a lot of flexiblity in the project. Everyone can be on the same sprint cycle, or individual teams can be on their own cycle.
The Most Common Configuration I Recommend
Here's how I'd set up a project that has one or two teams, which should be all that are on an Agile-based project anyway.
Notice I do not use the root level for the product backlog. Unfortunately, Microsoft doesn't help enough in setting this up.
Baskets-R-Us Website
|_Product Backlog
|_Sprint 2021-04-16
|_Sprint 2021-04-30
Why "product backlog"? In Team configuration > Iterations, there are two settings: Default iteration, Backlog Iteration.
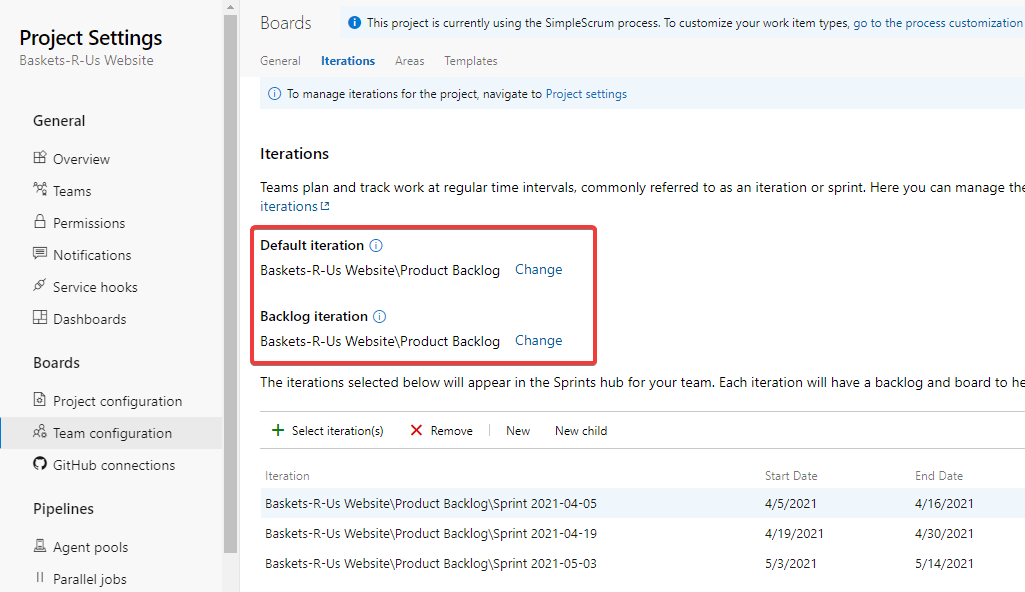
Default Iteration means "when I create a new work item, which iteration is it assigned to?" The default is @CurrentIteration. This is wrong! New work items should not be automatically added to the current sprint: that's contrary to Scrum thinking. Instead, I set Default iteration to the team's product backlog iteration.
Likewise, Backlog iteration means "When we look at our backlog, which iteration is at the root?" That should be, of course, the product backlog iteration. That's why I keep the naming clean.
Both teams on this project would use the same product backlog and iterations. The teams would have independent boards and work items because by default a team has its own area.
The result is that, in sprint planning, everyone would work from the same product backlog. Assuming Scrum, the project (product) should have a single Product Owner and Scrum Master shared by the two teams. When work items are assigned to iterations, they're also assigned to the team's area, allowing each team to filter for its work items in its boards.
Naming Iterations
Where organizations often go astray is naming.
Here's one way iterations might be organized for multiple teams. Again, notice my naming.
Baskets-R-Us Website <== root level folder
|_ eCommerce Product Backlog
|_2021-04-07
|_2021-04-30
|_Social Media Product Backlog
|_2021-04 05-16
|_2021-04 19-30
In this case, the teams within the project are working very independently. They don't share a backlog, instead each team maintains its own.
Yet Another Approach
Here's another--arguably better--way to organize multiple teams on a single Scrum-based project where the teams want to use their own sprint cycles. On a single project with just a couple of team. That's probably not a good idea. Keep the teams working as closely together as possible on the same project.
This rule of thumb doesn't apply on teams across projects, who shouldn't be constrained in how they independently work. They not only should have separate DevOps projects, but should be allowed to have their own process template.
Baskets-R-Us Website <== root level folder
|_Product Backlog
|_ eCommerce Sprints
|_2021-04-07
|_2021-04-30
|_Social Media Sprints
|_2021-04 05-16
|_2021-04 19-30
Given this organization, both teams would set their default and backlog iterations to "Product Backlog." The clear naming will help them find their iterations.
The fact that it's harder to work with the sprints might be a clue that the teams should share an iteration cycle.
The Wrong Way
Some organizations (believe) they want all employees and teams to use the same process, and even share the same backlog and board. This can be done in Azure DevOps, but frankly I think it's anti-Agile, anti-productive, and there's plenty of evidence to back me up.
Really, don't do this. It encourages a top-down, tightly-coupled, bureaucratic culture.
If you're determined, here's how you might do it by taking advantage of the little-used (for good reason) Areas feature.
Using multiple Areas should be reserved for really complex projects
Remember, work items are assigned to an Area and Iteration. What we're doing here is inverting (and subverting) the Azure DevOps structure by turning Areas into Projects.
|_MRU Process [THE Monsters-R-Us Process]
|_Monsters-R-Us Project [The ONLY project in the entire company]
|_MRU Team [EVERYONE including vendors. Iterations defined here. Backlog/Board defined here]
|_Area - MRU Website
|_Work Item(s) [assigned to Area and Iteration]
|_Area - MRU Mobile Applications
|_Work Item(s)
|_Area - MRU Developer Experience
|_Work Item(s)
|_Area - Internal DevOps Improvements
|_Work Item(s)
What this allows:
- Any employee can be assigned work in any area
- All work items are in a single, monolithic backlog that can be filtered by area
- Single, monolithic board that can be filtered by area or person
I'm sure someone will say Tags can be used for categorization and filtering. That's true, but adds complication.
Wrap Up
Azure DevOps is a quite capable suite of features that will work for many types of organizations. Because of that, it can be challenging to understand how to configure well.
Hopefully, this helps you along toward your own success.