UPDATE 2025
This article was intended to simply compare Framework and Core's default configuration approaches. However, reader Phil Ashby (thanks, Phil!) asked me to point out that Core (now just ".NET")-style configuration can be used in Framework. There are two approaches.
- Ben Foster showed in 2016 how to use Core-style configs in Framework. I've used this approach myself. Using .NET Core Configuration with legacy projects
- Unknown to me until Phil pointed it out, Microsoft included native support for ConfigurationBuilder starting in 2017 with .NET Framework 4.7.1. I haven't read this article, but it seems like a better solution. Configuration builders for ASP.NET
The Source Code
Code is found at:
https://github.com/bladewolf55/ConfigDemo
The Crucial Difference
.NET Framework applies environment configurations at build time, transforming environment-specific files to create a single configuration file for the deployed application. The application knows what environment it's supposed to be in, regardless of where it's deployed.
.NET/Core applies environment configurations at run time, using a specific environment variable, and can consume many configuration sources. The application asks what environment it's deployed in.
What's In Store
To show how Framework and Core differ, I'll show two ASP.NET MVC apps that do the same thing using both configuration strategies.
Brief History
.NET's configuration strategy has a checkered past. The .NET Framework depends on a single web.config or app.config. This is a hard dependency, meaning the file must exist. There's no way to construct a configuration in memory, and if you want to change a configuration value you have to save to the config file.
Over time, Microsoft tried various ways to allow changed the config file. The most common is arguably XML Transforms.
- Create a new build configuration such as "Staging"
- Add the corresponding config file,
web.Staging.config
- Write transformations that update the base
web.config
- Apply those transformations when publishing
There are several problems with this approach.
- It conflates build configuration with environment configuration.
- It's build-time, as noted above.
- By design, transformations can not be applied during development. You don't run the app in Visual Studio using the Staging configuration.
The last item was a sticking point for developers. Whether we shouldn't be running other than locally, we often need to. So, developers found various, non-supported ways to handle this. The most common is using a pre-build target to apply the transform.
This led to yet another problem: the web.config file kept changing and, with the rise of version control, was either accidentally checked in or had to be undone. There are some clever ways to manage that, but they're fundamentally workarounds.
Microsoft pretty much fixed all these problems in .NET Core. It was clear that developers needed to be able to consume environment-based configurations from arbitrary sources during run time.
In .NET/Core, the build configuration (Debug, Release) are separate from environment configurations. Build configurations determine things like assembly names, optimization settings, and whether you can debug.
I want to be able to Debug in any environment!
No matter the source, all environment configurations must be key-value pairs. A simple way to understand environment configurations is also a simple, supported case: when the application runs, it reads all its configuration from system environment variables.
Why Run-Time Configuration Matters: Build Once, Deploy To Many
Quick quiz: if I build the same .NET Framework code using three different transform files, are they all the same or different?
It's tempting to say, "Well, the code is the same, just the configs are different." But that's technically false. They are three different binaries. The code, in some way, could be different. This breaks a principle of continuous deployment.
Build once, deploy to many
We want to have one build artifact which we then deploy to any environment. This way, we know the code is the same, and the only difference is the environment. We also save considerable time in our CI/CD process.
Show Me the Code!
Our web site does just a couple of things:
- Display an environment-based setting called TestKey
- Display a customer from the environment's database
Database
The app assumes using a SQL Server; modify to your needs. Here's a script for creating the database, tables, and data.
use master
go
create database ConfigLocal
go
use ConfigLocal
go
create table Customers (
CustomerId int primary key identity,
Name varchar(max)
)
insert Customers(Name) values ('Local Louise')
select * from Customers
------------------------------------------------------
use master
go
create database ConfigDevelopmentShared
go
use ConfigDevelopmentShared
go
create table Customers (
CustomerId int primary key identity,
Name varchar(max)
)
insert Customers(Name) values ('Development Shared Dagmar')
select * from Customers
------------------------------------------------------
use master
go
create database ConfigStaging
go
use ConfigStaging
go
create table Customers (
CustomerId int primary key identity,
Name varchar(max)
)
insert Customers(Name) values ('Staging Sierra')
select * from Customers
------------------------------------------------------
use master
go
create database ConfigProduction
go
use ConfigProduction
go
create table Customers (
CustomerId int primary key identity,
Name varchar(max)
)
insert Customers(Name) values ('Production Pavla')
select * from Customers
------------------------------------------------------
.NET Framework Version
We're going to fly through the coding part while calling out what matters.
- Create new ASP.NET Web Application (.NET Framework) project named "ConfigFramework"
- Choose MVC template
- Add
EntityFramework NuGet package
- Add Data folder
- Add
Customer.cs
namespace ConfigFramework.Data
{
public class Customer
{
public int CustomerId { get; set; }
public string Name { get; set; }
}
}
- Add
ConfigDb.cs
using System.Data.Entity;
namespace ConfigFramework.Data
{
public class ConfigDb: DbContext
{
public DbSet<Customer> Customers { get; set; }
public ConfigDb(): base("name=ConfigDb") { }
}
}
- Add
Models/CustomerViewModel.cs
namespace ConfigFramework.Models
{
public class CustomerViewModel
{
public int CustomerId { get; set; }
public string Name { get; set; }
public string TestKey { get; set; }
}
}
- Replace code in
Controllers/HomeController.cs
using ConfigFramework.Data;
using ConfigFramework.Models;
using System.Linq;
using System.Web.Mvc;
namespace ConfigFramework.Controllers
{
public class HomeController : Controller
{
ConfigDb db = new ConfigDb();
public ActionResult Index()
{
var customer = db.Customers.First();
var model = new CustomerViewModel()
{
CustomerId = customer.CustomerId,
Name = customer.Name,
TestKey = Settings.TestKey
};
return View(model);
}
}
}
- Replace code in
Views/Home/Index.cshtml
@model ConfigFramework.Models.CustomerViewModel
<p>Customer: @(Model.CustomerId.ToString() + " " + Model.Name)</p>
<p>Key: @(Model.TestKey)</p>
How Do We Read the Environment Configuration?
- Add at root
Settings.cs
using System.Web.Configuration;
namespace ConfigFramework
{
public static class Settings
{
public static string TestKey = WebConfigurationManager.AppSettings["TestKey"];
}
}
- Update
web.config
<!--> Add under configuration > configSections-->
<connectionStrings>
<add name="ConfigDb" connectionString="Server=.;Database=ConfigLocal;Trusted_Connection=True"
providerName="System.Data.SqlClient"/>
</connectionStrings>
<!-- Add to appSettings> -->
<add key="TestKey" value="Local"/>
- Open Build > Configuration Manager
- Drop down Active solution configuration > New
- Name = "Development", Copy settings from = "Debug", Create new project configurations = checked
- OK
- Do the same to create Staging and Production configurations
- If you don't immediately see the
Web.[environment].config files under web.config
- Right-click
web.config
- Choose Add config transform
- Update
Web.Debug.config
<?xml version="1.0" encoding="utf-8"?>
<configuration xmlns:xdt="http://schemas.microsoft.com/XML-Document-Transform">
<connectionStrings>
<add name="ConfigDb" connectionString="Server=.;Database=ConfigLocal;Trusted_Connection=True"
providerName="System.Data.SqlClient"
xdt:Transform="SetAttributes" xdt:Locator="Match(name)"/>
</connectionStrings>
<appSettings>
<add key="TestKey" value="Local" xdt:Transform="SetAttributes" xdt:Locator="Match(key)"/>
</appSettings>
</configuration>
- Similarly, update Development, Staging, and Release with these values:
- Development: Database=ConfigDevelopmentShared, TestKey value="Development"
- Staging: Database=ConfigStaging, TestKey value="Staging"
- Production: Database=ConfigProduction, TestKey value="Production"
- Using an external editor, modify
ConfigFramework.csproj. Add this task node at the bottom.
This is the magic sauce that allows running the app in Visual Studio using different configurations
<Target Name="BeforeBuild">
<TransformXml Source="Web.config" Transform="Web.$(Configuration).config" Destination="Web.config" />
</Target>
Run It
Setting the configuration to Debug and pressing F5 should, at this point, open the web site and display something like this:
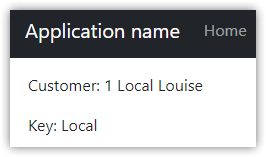
You might get a message about enabling debug. Go ahead and do that. We aren't going to disable debugging in our environment files, but in a real application we would.
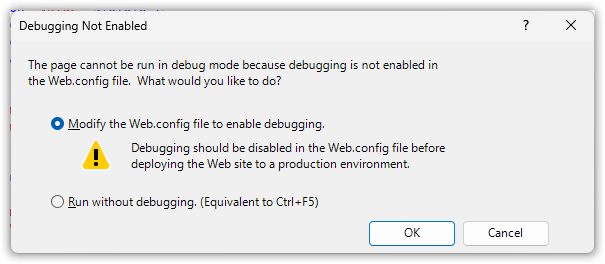
Changing the configuration displays different data.
Key Points
Environments are linked to build configurations.
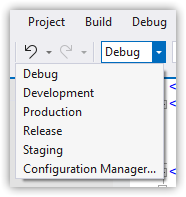
Web site is run using one IIS Express setup, regardless of configuration.
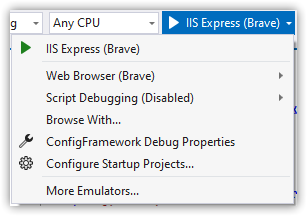
.NET Framework has no dependency injection out of the box. So, we're using a global, static Settings file. This means unit testing depends on the unit testing project having a web.config file that's configured appropriately rather than injecting configurations.
While it's possible to get settings from other sources (such as a database), it's custom work.
.NET/Core Version
The steps here are very similar in .NET Core 3+ and .NET 5+. This code uses .NET 6 and includes improved C# language features such as file-scoped namespaces.
- Create a new ASP.NET Core Web App (Model-View-Controller) project named "ConfigCore"
Important Be sure to use the Model-View-Controller template
- Add
Microsoft.EntityFrameworkCore.SqlServer NuGet package
- Add Data folder
- Add
Customer.cs
namespace ConfigFramework.Data;
public class Customer
{
public int CustomerId { get; set; }
public string Name { get; set; } = string.Empty;
}
- Add
ConfigDb.cs
using Microsoft.EntityFrameworkCore;
namespace ConfigFramework.Data;
public class ConfigDb: DbContext
{
public DbSet<Customer> Customers { get; set; }
public ConfigDb(DbContextOptions options) : base(options) { }
}
- Add
Models/CustomerViewModel.cs
namespace ConfigFramework.Models;
public class CustomerViewModel
{
public int CustomerId { get; set; }
public string Name { get; set; } = string.Empty;
public string TestKey { get; set; } = string.Empty;
}
- Replace code in
Controllers/HomeController.cs
There's more code, but we're also doing more with dependency injection
using ConfigFramework.Data;
using ConfigFramework.Models;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Options;
namespace ConfigCore.Controllers;
public class HomeController : Controller
{
readonly ILogger<HomeController> _logger;
readonly ConfigDb db;
readonly Settings settings;
public HomeController(ILogger<HomeController> logger, ConfigDb db, IOptions<Settings> settings)
{
_logger = logger;
this.db = db;
this.settings = settings.Value;
}
public IActionResult Index()
{
var customer = db.Customers.First();
var model = new CustomerViewModel()
{
CustomerId = customer.CustomerId,
Name = customer.Name,
TestKey = settings.TestKey
};
return View(model);
}
}
- Replace code in
Views/Home/Index.cshtml
@model ConfigFramework.Models.CustomerViewModel
<p>Customer: @(Model.CustomerId.ToString() + " " + Model.Name)</p>
<p>Key: @(Model.TestKey)</p>
How Do We Read the Environment Configuration?
Here's where we see how very different Framework and Core are
- Add at root
Settings.cs
Note this does not directly read configurations. Properties get set later.
namespace ConfigCore;
public class Settings
{
public const string AppSettings = "AppSettings";
public string TestKey { get; set; } = String.Empty;
}
- Update
Program.cs
Set up the DbContext and configuration file dependency injection
// Add after builder.Services.AddControllersWithViews();
builder.Services.AddDbContext<ConfigDb>(options => options.UseSqlServer("name=ConnectionStrings:ConfigDb"));
builder.Services.Configure<Settings>(builder.Configuration.GetSection(Settings.AppSettings));
- Add a file named
appsettings.Development.json
The section names are arbritary, but we still have a supported convention of sections named
ConnectionStrings and AppSettings.
{
"Logging": {
"LogLevel": {
"Default": "Information",
"Microsoft.AspNetCore": "Warning"
}
},
"ConnectionStrings": {
"ConfigDb": "Server=.;Database=ConfigLocal;Trusted_Connection=True;TrustServerCertificate=true;"
},
"AppSettings": {
"TestKey": "Development"
}
}
- Add the remaining files with these environment names:
These files are one of several source that .NET checks for when configuring
- DevelopmentShared: Database=ConfigDevelopmentShared, TestKey value="Development"
- Staging: Database=ConfigStaging, TestKey value="Staging"
- Production: Database=ConfigProduction, TestKey value="Production"
- Update
Properties/launchSettings.json. Replace the IIS Express entry with these new entries.
"IIS Express Development": {
"commandName": "IISExpress",
"launchBrowser": true,
"environmentVariables": {
"ASPNETCORE_ENVIRONMENT": "Development"
}
},
"IIS Express Development Shared": {
"commandName": "IISExpress",
"launchBrowser": true,
"environmentVariables": {
"ASPNETCORE_ENVIRONMENT": "DevelopmentShared"
}
},
"IIS Express Staging": {
"commandName": "IISExpress",
"launchBrowser": true,
"environmentVariables": {
"ASPNETCORE_ENVIRONMENT": "Staging"
}
},
"IIS Express Production": {
"commandName": "IISExpress",
"launchBrowser": true,
"environmentVariables": {
"ASPNETCORE_ENVIRONMENT": "Production"
}
}
Run It
Keep the build configuration as Debug, choose the IIS Express Development runtime configuration and F5 to run.

You should see this:

Key Points
Build configurations are not usually customized
IIS Express can start as other environments
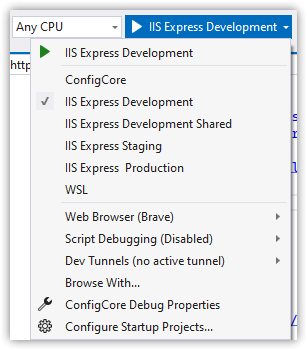
Environment is an environment variable, ASPNETCORE_ENVIRONMENT
Environment settings come from many sources, including appsettings.[Environment].json files.
launchSettings.json is used to set the environment variable for local development.
Important
It may not be obvious, but if you deployed the application to a web server running IIS and wanted it to run as Staging, you would have to add/set the ASPNETCORE_ENVIRONMENT to "Staging". Without that, the app will run as Production by default.
Time Out! What's With DevelopmentShared? And How Does All This Work?
In .NET/Core
WebApplication.CreateBuilder reads a bunch of configuration sources by default, in a specific order.- The "Development" environment has special behaviors that you don't know about unless you read the documentation, which will catch you by surprise.
- "Development" is intended for local work
There's some problematic--but understandable--mental modeling at work here that I've seen over the years. Just as Microsoft conflated build and environment configurations, developers have conflated Debug and Development. .NET Framework accidentally encouraged developers to think of Debug as "local development." Many teams have a shared development environment (shared web and database). So, they naturally added a Development configuration that meant "remote."
In .NET/Core, Debug has nothing to do with environment, and Development equals local. This is stated in the documentation, and is evident in code like this from Program.cs
if (!app.Environment.IsDevelopment())
{
app.UseExceptionHandler("/Home/Error");
// The default HSTS value is 30 days. You may want to change this for production scenarios, see https://aka.ms/aspnetcore-hsts.
app.UseHsts();
}
Development is the environment where we'd be calling other services with local ports, such as https://localhost:50334.
But more importantly, when the configuration is built up, if the ASPNETCORE_ENVIRONMENT environment is "Development", user secrets are read if they exist. This is important for keeping sensitive information secure.
Default application configuration sources
I don't like it, but as far as I can tell these hidden behaviors are only enabled if ASPNETCORE_ENVIRONMENT is set to "Development". Not "Dev", and not any other user-defined value. You can, of course, easily customize the builder, but it's critical to know the default behaviors.
Also, I prefer sticking with defaults when I can.
So, that's why I added a DevelopmentShared environment. I would assume that any secrets needed in a shared environment come from a shared source such as Azure Key Vault.
How many configuration sources are looked up by default? Six, and in this order. The later sources will override values of the same keys in earlier sources.
- Fallback host configuration
appsettings.jsonappsettings.[Environment].json- User secrets
- Environment variables
- Command-line arguments
Proving How It Works
As stated earlier, one goal of the new configuration approach is "build once, deploy to many," meaning I should be able to control my application's settings without changing the appsettings files. Let's try that.
- Run using IIS Express Staging.
- You should see customer "Staging Sierra" and key "Staging"
We'll run the app using a different environment, similar to running in IIS. For convenience, we'll do this from the command line with in-process environment variables.
- Open PowerShell
- Run
# cd [path/to/ConfigCore solution]
$Env:ASPNETCORE_ENVIRONMENT = "Production"
dotnet run --project ConfigCore --no-launch-profile
- The site runs using the Kestral webhost. Open whatever URL is displayed, typically http://localhost:5000
You should see customer = "Pavla" and key = "Production"
Ctrl-C to stop the site.- Run
$Env:AppSettings__TestKey = "Blamo"
dotnet run --project ConfigCore --no-launch-profile
- Once running, refresh the page.
The key should change to "Blamo."
Why is the environment variable name AppSettings__TestKey with the double-underscore? That's a Microsoft convention that allows converting the key to a hierarchy of the form "AppSettings:TestKey". In fact, the json file also converts to that format, as does any other configuration source. The double-underscore works with Linux environment variables.
When you run using Visual Studio, ASPNETCORE_ENVIRONMENT is usually set in launchSettings. But it doesn't have to be. If you delete the environmentVariables key, the app will either run as Production (the default) or as whatever is set for ASPNETCORE_ENVIRONMENT in the user profile or system environment variables.
Note: Remember you have to close/reopen Visual Studio to see new environment variable changes.
Wrap Up
Microsoft fundamentally changed how configuration works in .NET/Core compared to Framework. They solved many problems and provided flexible and testable methods. The biggest barrier I've seen to using the new configuration strategies is understanding what changed and how they're intended to work.

